In Power BI, Normalizing a Dimension is (NOT) Crucial for Usability and Performance
Okay, Power BI community, we have a problem. 80+ votes is already enough to confirm that we indeed have a problem.
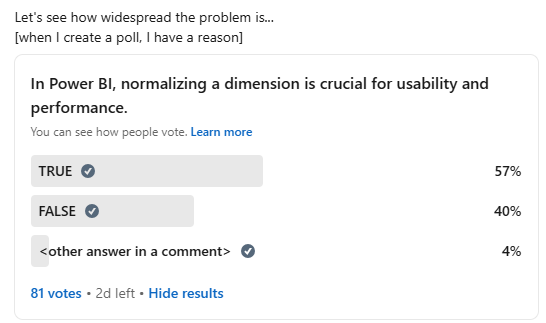
“In Power BI, normalizing a dimension is crucial for usability and performance.”
🛑 Wrong!
Generally speaking, normalization is not useful for data analysis. But this term is not as straightforward as you may think.
“Database normalization is the process of structuring a relational database in accordance with a series of so-called normal forms in order to reduce data redundancy and improve data integrity. It was first proposed by British computer scientist Edgar F. Codd.” — Wikipedia
One of the objectives of normalization was stated by Codd as “to free the collection of relations from undesirable insertion, update, and deletion dependencies.”
💡 Wait, in data analysis we have no insertions, updates, and deletions. Normalization principles were never intended to help data analysts.
Normalization principles have been designed for OLTP (Online Transaction Processing) systems, systems designed to support, for example, financial transactions.
💡 Denormalized data and redundancy are not issues in OLAP (Online Analytical Processing) systems. There is an ETL process to deal with integrity, so we don’t need to handle it when querying data. The purpose of OLAP systems is to query the data: read, filter, and aggregate large amounts of data.
Redundancy in this case is not an enemy. A non-normalized dimension table in a star schema data model simplifies DAX and increases performance. Normalization of dimensions in Power BI is not going to improve usability (it will be harder to work with filters, slicers, and DAX), and it’s not going to improve performance (there will be more relationships to handle within a query).
From another point of view, what exactly is “normalization”? Achieving 1NF, 2NF, 3NF? If your data source is a flat table, then creating a star schema likely introduces some normalization (of a fact table only). If your data source is an OLTP system with already normalized data, then creating a star schema requires denormalization.
But for sure, a dimension in a Power BI data model is usually not in a normal form (maybe in 1NF, but even that is not necessary). Normalization converts a star schema into a snowflake schema. In some cases, we need to change some dimensions into a snowflake form, but that’s an exception, not a rule, and not every snowflake suitable for data analysis will be in, for example, 3rd normal form.
I mentioned “a dimension” in my question to limit possible interpretations, but a fact table in a star schema can also be in a non-normalized form. You can even have duplicates in a fact table (if they are not results of errors but meaningful facts). This is not what negatively affects usability and performance.
Books about dimensional modeling I recommend to read:
📖 Star Schema: The Complete Reference by Christopher Adamson
📖 The Data Warehouse Toolkit: The Definitive Guide to Dimensional Modeling by Ralph Kimball